
Quelle/n:
https://siderite.dev/blog/how-to-translate-t-sql-datetime2-to.html Beim SQL war DATEDIFF schon länger bekannt und üblich. Leider konnten Zeiträume viel zu schnell größer sein, als dies man z.B. in Sekunden erfassen konnte. Quelle/n: Quelle/n: Das Azure Data Studio ist ein kostenfreies Tool von Microsoft und wenn die drei richtigen Extension installiert sind, können Datenbank-Projekte über Git synchronisiert werden. How to Use Azure Data Studio with Database Projects and Source Control
Hinweis/e wieso man Azure Data Studio probieren könnte und möglichweise nicht VS benutzen muss: Hinweis: Das „Visual Studio Code“ ist auch von Microsoft und kostenlos und ist eigentlich nur eine „Editor“ und ist nur namentlich verwandt mit dem „Visual Studio“. Es gibt zwar einige Extensions, ist aber kein Ersatz für die beiden vorher genannten Tools (Visual Studio + Azure Data Studio). /* Befehle Anlage von Tabellen, Prozeduren etc.: https://docs.oracle.com/cd/E18283_01/server.112/e17120/tables003.htm#i1106335 https://stackoverflow.com/questions/1799128/oracle-if-table-exists https://docs.oracle.com/cd/E10405_01/appdev.120/e10379/ss_oracle_compared.htm https://asktom.oracle.com/pls/apex/f?p=100:11:::::P11_QUESTION_ID:9541246000346968042 Unterschiede der Datentypen bzw. das Mapping von Datentypen: https://www.mssqltips.com/sqlservertip/2944/comparing-sql-server-and-oracle-datatypes/ Die Neuanlage von Oracle Datenbanken sind nicht so einfach wie MS SQL Server…. Ich habe mehrere Beispiele in dieser Website, wo ich keinen Cursor benutze. Cursor müssen sauber beendet u. gelöscht werden. Das kann früher oder später für Benutzer Schwierigkeiten machen… Dieser Frage sind andere auch nachgegangen: Suchbegriffe: Cursor, Loop, Schleife, SQL, While Ganze Tabellen einer Datenbank sichern Es wird dabei auch T-SQL Code bereitgestellt, um diese komprimierten und gesicherten Daten, ohne Aufwand lesbar zu machen. Durch diese Form der Sicherungen, können mglw. komplette ETL-Strecken, zu erneut eingespielt werden. Ganze Tabellen einer Datenbank sichern.docx Limits: Ein Feld mit dem Typ NVARCHAR(MAX) kann nicht mehr als 2 GByte enthalten How to easily downgrade SQL Server from Enterprise to Developer/Standard Edition – Datarrett Downgrade from SQL Server Enterprise Edition to Standard Edition (mssqltips.com) Wenn die o. g. Lösung nicht ausreichend ist und ggf. komplett neu aufgesetzt werden müsste, hier können vielleicht vorher die SIDs gesichert und später wieder eingespielt: Feature der Enterprise-Edition könnten zu Problemen führen? Beim Lesen von T-SQL im SSMS fehlt immer wieder eine Formatierungs-Hilfe. Ggf. ist noch das .NET Framework 2.0 nötig: Das SSMS muss ggf. neu gestartet werden und dann ist im Menü „Tools“ der Punkt „Format T-SQL Code“ Benutzung: The problem may have been caused by a configuration change or by the installation of another extension. Restarting Visual Studio could help resolve this issue. Continue to show this error message? Lösung: In einzelnen Fällen war das Menü deaktiviert („grau“). In dem Fall hat mir dieser Link geholfen die Konfiguration des SSMS anzupassen („ssms.exe.config“): https://stackoverflow.com/questions/63313632/poor-mans-t-sql-formatting-add-in-format-t-sql-code-option-disabled-in-sql-ser Technisch kann man beide Modi bereitstellen indem zusätzliche Instanzen bereitgestellt werden. Wenn jedoch bei der Installation der SSAS Modus „falsch“ installiert wurde, und einfach nur richtigen Modus haben will, der könnte das erreichen, indem die msmdsrv.ini angepasst wird und dann die Instanz einfach neu starten: Bei Multidimensional: <DeploymentMode>0</DeploymentMode> Bei Sharepoint: <DeploymentMode>1</DeploymentMode> Bei Tabellarisch: <DeploymentMode>2</DeploymentMode> Die ini-Datei ist bei der Standardinstallation: Quelle/n: Prinzipiell sollte es möglich sein eine Datenbank oder einzelne Dateien, z.B. das LOG zu verkleinern. Aber diese werden niemals kleiner, als die „Inital Size“. Wenn es jedoch immer noch nicht funktioniert, kann es an vorhandenen Indizes liegen, die auch sehr stark fragmentiert sein können. Gute „vorbereitete Lösung“ habe ich gefunden bei: https://blog.pmd-media.com/2009/10/08/howto-verkleinern-einer-microsoft-sql-server-datenbank/
Problem Darstellung eines Ergebnisses per T-SQL möchte man gelegentlich unterschiedlich formatieren.
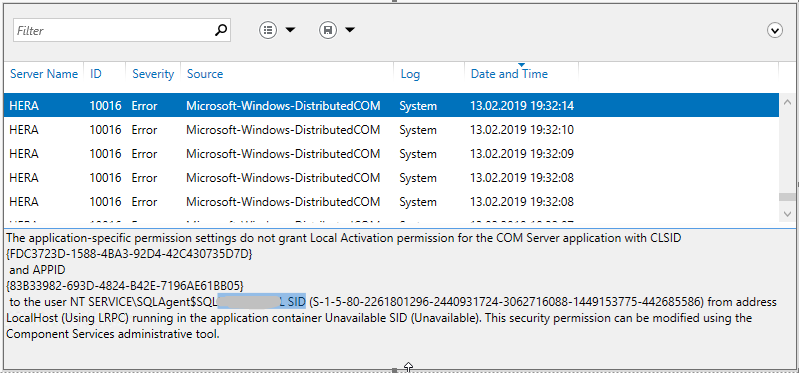
Quelle: https://stackoverflow.com/questions/4377352/how-do-i-format-a-number-with-commas-in-t-sql Problem: Das SSMS (SQL Server Management Studio) hängt alle paar Minuten – Auch ein Neustart des SSMS bringt nichts. Ursache: Eine T-SQL Query ist syntaktisch defekt und das SSMS „wild“ zu werden. Es scheint mit einem Zusammenhang mit dem IntelliSense zu haben. Lösung: Korrektur des T-SQL Code und ein paar Minuten geduldig sein, CPU verringert sich schneller und das RAM normalisiert sich etwas später! Ähnliche Feststellungen: Es sind neue „Error“ Einträge mit dem ID=10016. Und der Text: The application-specific permission Settings do not grant Local Activivation permission for the COM Server application with CLSID {….} and APPID {….} to the user ….. SID {….} from address localHost (Using LRPC) running in the application container Unavailable SID {….}. This security permission can be modified using the Component Services administrative tool. Link: https://answers.microsoft.com/en-us/windows/forum/windows_8-performance/application-container-unavailable-sid-unavailable/4ec39b15-1f43-4d7a-bbf6-11706a685b7c Nach dem Klären, dass es sich um die „COM Server application“ handelt „Microsoft.SQLServer.Dts.Server.DtsServer“ und in den „Component Services“ den „Microsoft SQL Server Integration Service 11.0“ ging ich davon es aus reichen sollte dem fraglichem „Agent-User“ die Rechte zu den Datenbanken „msdb“ und „SSISDB“ zu erteilen.
Weiterhin erschien die Fehlermeldungen und musste dem oberem Link folgen und die „Component Services“ anzupassen. in Arbeit Es gibt prinzipiell verschiedene Stellen, wohin man den Code ablegen kann, damit der SQL Server diesen aufruft. Wobei ich derzeit diese letzte Variante „SSIS Catalog“ in aktuellen Datenbanken. Es wird in der Datenbank automatisch eine Datenbank „SSISDB“ und soweit die Service Integration auch installiert ist, gibt es auch einen „Integration Services Catalog“. Beim Erstem Aufruf muss ein Passwort hinterlegt werden (IMHO unveränderbar). Es wird dann der erste Ebene „SSISDB“ angelegt und darunter können/müssen für jede SSIS-Solution, die man hier ablegt gleich einen neuen Ordner anlegen. Daher bitte die Ordner die Ordnernamen sprechend festlegen (wieder IMHO kaum unveränderbar).
Hier meine Schritte: Das Anlegen von Agent Jobs sind eigentlich recht einfach. Aber gilt nicht für den allerersten Job;-). Aber es sind mehrere Schritte: Möglicherweise fehlen noch Rechte: Lösung: Rolle ssis_admin in SSISDB und Rolle db_ssisoperator in msdb hinzufügen. Falls dann sind aber diese „User“ zwar in den beiden Datenbank (jeweils unter: Security / Users) sichtbar, aber so mit einem „X“ oder „irgendwie deaktiviert“… Dann müssen diese User auch in der Datenbank hinzugefügt werden – wie im T-SQL Code: Es gibt tatsächlich zwei völlig unterschiedliche Ansätze…. Ich nutze diese kürzere – vielleicht etwas älter – Variante: Die zweite Variante benötigt das „XACT_STATE“ und liest sich noch komplizierter und werde ich nur nutzen, wenn ich mit dem o. g. T-SQL Code nicht weiter komme. Aber beschrieben sind beide Wege von Microsoft in dem u. g. Link Link: Um das Einrichten von Database Mail-Account können diese Schritte manuell vornehmen werden: Beschreibung: Vermutlich ist diese Bestätigung notwendig: Und nun dem „Profil“ ein Namen geben und einen SMTP-Account hinterlegen: Und nun sind die Zugriffsdaten des Exchange Server notwendig… Port, SSL-Häkchen und E-Mail Server sind den Adminstratoren bekannt Nach dem „OK“ sind wir wieder zurück: Und müssen „Next“ klicken und in diesem Schritt muss das Profil aktiviert werden… In diesem nächstem Schritt müssen wir vermutlich die maximale Größe von E-Mails anpassen. Eine „0“ mehr, also 10 MB erlauben: Dann wird das lediglich noch einmal zusammengefasst und man muss mit „Finish“beenden. Danach sollten alle fünf Aktionen mit „Success“ beendet sein. Und der Versand von E-Mails kann jetzt getestet werden: Falls die Test-Email nicht am Ziel angekommen ist, finden Sie den dort wo die „Send Test E-Mail…“ Popup war, auch das „View Database Mail Log“… Typische Fehlerldung: „The SMTP Server Requires a Secure Connection or the Client was not Authenticated“
Links: Links: Fehlermeldungen: Msg 22050, Level 16, State 1, Line 3 Hinweis: Die gleiche Fehlermeldung bekommt man auch, wenn das „QuerySQL“ nicht mit einer vollständigen „Select * FROM Datenbank.Schema.Tabelle“ Formalimus arbeitet. Diese Stored Procedure ruft die „QuerySQL“ in einer neuer Query Umgebung (IMHO: in Master)… Und die Fehlermeldung halte ich als irreführend! Zugriff auf SQL Server über eine AD-Gruppe: Link: https://stackoverflow.com/questions/5029014/how-to-add-active-directory-user-group-as-login-in-sql-server https://docs.microsoft.com/en-us/sql/relational-databases/security/authentication-access/create-a-database-user?view=sql-server-2017 Damit die Domänen-User auch Daten von der Datenbank lesen können, sind weitere Rechte notwendig. Schemabindung ist sehr interessant, weil dann komplexe Views plötzlich schnell aufgerufen werden können. Aber hat auch Voraussetzungen und sogar Nachteile haben. Z.B. sind dann alle Tabellen, die auf den View zugreifen gesperrt , gegen struktureller Änderungen. Das bedeutet, wenn ein neues Feld in die Tabelle soll, muss der/die View/s gelöscht werden und dann wieder angelegt werden. Die alle Indizes, dieser betroffenen View/s müssen dann auch wieder angelegt werden. Voraussetzungen sind recht komplex und sind in der Quelle reichlich beschrieben. Aber es wird keine Fehlermeldung geben, lediglich kann es sein, dass der „View with schemabinding“ lediglich die Daten nicht persistent speichert. Aber damit man ganz schnell feststellen kann welche SET-Options im System eingerichtet sind ist in einer „neuen“ SSMS-Query hiermit leicht abfragen: Weil die neue STRING_AGG() nicht mehr als 8000 Zeichen akzeptiert, muss man sich weiterhin behelfen: Gelegentlich möchte man sich T-SQL generieren lassen und dann auch noch starten zu lassen. Als Beispiel ist eine Kontrolle, ob wirklich alle Tabellen „truncated“ wurde…. Manchmal kommt noch eine Tabelle hinzu und schon wird vergessen dass auch diese neue Tabelle auch geleert sein sollte. Das Beispiel soll nur zeigen, wie es möglich ist – der Befehl STRING_AGG funktioniert erst ab SQL Server 2016 (Vorher wurde XML in dem SQL eingebaut): Hinweis: Der Befehlt STRING_AGG() darf jedoch maximal 8000 Zeichen produzieren – daher wird dies im Zweifel nicht benutzt werden kann! Es ist zwar nicht weiter wichtig, aber wenn es irritiert oder konkrete Fragen gestellt wird, habe auch ich gesucht und wurde fündig…. Es ist lediglich der SSMS nicht in der Lage den Status einzelner Dienste des angebundenen fernen SQL Servers
Link 1: https://dba.stackexchange.com/questions/176666/blue-icon-with-question-mark-what-does-it-mean
Hier wird klar der Port 135 des Firewall und es ist von Microsoft mehr Information zu beschaffen:
Es ist zwar möglich die alle Ports festzustellen Immer wieder wäre es schön kurzeitig andere Einstellungen zu nutzten. Speziell damit T-SQL Batches sehr unabhängig arbeiten können: ACHTUNG: Variablen sind alle verloren nach jedem „GO“ – auch wenn ein GO in einem Kommentar seht ist das meist verloren! Häufig scheinen Abfragen überraschend langsam sein, oder immer langsam werden…. Als Tunings-Maßnahme lohnen sich meist als erster Versuch Indizes in der Datenbank. Lediglich sind bestimmte Rechte für der u. g. TSQL-Code notwendig Das führt zu der Fehlermeldung: Die Lösung ist: Auch andere Quelle/Beschreibung: http://sqldbpros.com/2012/08/sql-create-schema-if-not-exists/ Hinweis: Standardmäßig sind jedoch nur 100 Rekursionen erlaubt und werden mit einem Fehler abgerochen. Lösung: Ganz an das Ende des T-SQL Code, also auch hinter „WHERE“-Bedingung/en und „Order BY“:
Problem 1: Nicht immer sind die CRLF verblieben
Falls ein Backup sehr viel Zeit braucht, wäre es schön, wenn man einmal feststellen kann, wie weit das Backup ist:
Übrigens: Ich habe die Dauer von Backups gebraucht, als Probleme beim Zugriff auf ein RAID System einmal bestand…
Falls die Wiederherstellung einer Datenbank immer noch nicht fertig ist, wäre es schön, wenn man einmal feststellen kann, wie weit die Wiederherstellung zumindest ist…
Seit SQL Server 2016 gibt es einige neue Funktionen. Ein Beispiel mit dem Code wesentlich kürzer ist die table based function „string_split()“. What is a system-versioned temporal table? Beispiel: Video: https://channel9.msdn.com/Shows/Data-Exposed/Temporal-in-SQL-Server-2016 Weitere sehr gute Beschreibung: http://sqlhints.com/tag/for-system_time-as-of/ Quelle:
DATEDIFF_BIG
Microsoft bietet einige neue Prozeduren, die im Namen zusätzlich ein „…_BIG“. Einsetze ich das DATEDIFF_BIG speziell beim LOGGING.
Aber auch ein DATEDIFF_BIG kann zu einer Fehlermeldung führen bzw. zu einem Überlauf wenn man z.B. die Nanosekunden zwischen Heute und dem 01.01.0001 berechnet…
Mir reichen zur Genauigkeit die Mikrosekunden aus und dann kann das Ergebnis in einer Variablen „bigint“ speichern.
https://learn.microsoft.com/de-de/sql/t-sql/functions/datediff-big-transact-sql?view=sql-server-ver16Daten/Parameter austauschen zwischen den Steps in Agent-Jobs
https://www.mssqltips.com/sqlservertip/5731/how-to-pass-data-between-sql-server-agent-job-steps/Azure Data Studio
Gelegentlich stelle ich fest, dass werden einzelne Dateien eben doch nicht synchronisiert werden und mal sind Order mit Leerzeichen, mal ohne Leerzeichen ( „Stored Procedures“, „StoredProcedures“)
Perfekt ist das auch nicht. MS eben.
Metadaten: Information über SQL Tabellen u. Felder
Metadaten: Information über SQL Tabellen u. Felder
*/
--V1 (einfach)
Select ORDINAL_POSITION, TABLE_SCHEMA, TABLE_NAME
, IS_NULLABLE, COLUMN_DEFAULT
, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION
, NUMERIC_PRECISION_RADIX, NUMERIC_SCALE, DATETIME_PRECISION
from INFORMATION_SCHEMA.COLUMNS
where TABLE_SCHEMA='dbo'
and TABLE_NAME='Errors'
Order by ORDINAL_POSITION--V2 (ausführlicher)
Select c.ORDINAL_POSITION, c.TABLE_SCHEMA, c.TABLE_NAME, c.IS_NULLABLE, Coalesce(c.COLUMN_DEFAULT,'') as COLUMN_DEFAULT
,Case when pk.COLUMN_NAME is NULL then '' else 'PK' end as HAS_PRIMARY_KEY
--,c.DATA_TYPE, c.CHARACTER_MAXIMUM_LENGTH, c.NUMERIC_PRECISION, c.NUMERIC_PRECISION_RADIX, c.NUMERIC_SCALE, c.DATETIME_PRECISION
,CASE
WHEN c.[data_type] IN (
'tinyint'
,'smallint'
,'int'
,'bigint'
,'float'
)
THEN c.[data_type]
WHEN c.[data_type] IN ('bit')
THEN c.[data_type]
WHEN c.[data_type] IN ('decimal')
THEN c.[data_type] + '(' + CAST(c.[numeric_precision] AS NVARCHAR(10)) + ',' + CAST(c.[numeric_scale] AS NVARCHAR(10)) + ')'
WHEN c.[data_type] IN (
'smallmoney'
,'money'
)
THEN c.[data_type]
WHEN c.[data_type] IN (
'char'
,'nchar'
,'varchar'
,'nvarchar'
)
AND c.[character_maximum_length] < 0
THEN c.[data_type] + '(MAX)'
WHEN c.[data_type] IN (
'char'
,'nchar'
,'varchar'
,'nvarchar'
)
AND c.[character_maximum_length] >= 0
THEN c.[data_type] + '(' + CAST(c.[character_maximum_length] AS NVARCHAR(10)) + ')'
WHEN c.[data_type] IN (
'date'
,'time'
,'datetime'
)
THEN c.[data_type]
WHEN c.[data_type] IN ('datetime2')
THEN c.[data_type] + '(7)'
WHEN c.[data_type] IN ('uniqueidentifier')
THEN c.[data_type]
WHEN c.[data_type] IN ('xml')
THEN c.[data_type]
WHEN c.[data_type] IN ('geography')
THEN c.[data_type]
WHEN c.[data_type] IN ('hierarchyid')
THEN c.[data_type]
ELSE c.[data_type]
END AS [data_type_explicit]
from INFORMATION_SCHEMA.COLUMNS as c
left outer join INFORMATION_SCHEMA.KEY_COLUMN_USAGE as pk
ON c.TABLE_CATALOG=pk.TABLE_CATALOG and c.TABLE_SCHEMA=pk.TABLE_SCHEMA and c.TABLE_NAME=pk.TABLE_NAME and c.COLUMN_NAME=pk.COLUMN_NAME
where c.TABLE_SCHEMA='dbo'
and c.TABLE_NAME='Errors'
Order by c.ORDINAL_POSITIONBenutzung von Oracle (Tabellen, Prozeduren)
https://learn.microsoft.com/en-us/sql/relational-databases/replication/non-sql/data-type-mapping-for-oracle-publishersSQL: WHILE Loop oder Cursor?
Ohne einen Cursor zu benutzen, wäre eine „ToDo-Tabelle“ anzulegen und diese „abarbeiten“. Ich benutzte meist ein eigenes „IstErledigt-Feld“ und hake jeden Satz in einer Schleife ab. Erscheint mir technisch einfacher.
https://www.mssqltips.com/sqlservertip/6148/sql-server-loop-through-table-rows-without-cursor/Ganze Tabellen einer Datenbank sichern als einzelner Datensatz
Es werden in diesem Beispiel in einer Schleife eine Tabelle einer Staging-Datenbank in einem einzigem Feld eines Satzes in der [BackupsTabelle] in einer anderen Datenbank [BackupDB] gesichert.Downgrade MS SQL Server, SSAS, etc.

SQL Formatter (leider nur bis SSMS 2019)
Praktisch fand ich:
Quelle/n (des gleichen Entwicklers):
• https://github.com/TaoK/PoorMansTSqlFormatter
Ist GitHub, aber nur schwierig die richtige *.msi zu finden
• http://architectshack.com/PoorMansTSqlFormatter.ashx#Download_15
Hier muss man die „Extension for CURRENT VERSION of SSMS….“ suchen und kann die PoorMansTSqlFormatterSSMSPackage.Setup.1.6.16.msi laden und installieren.
Download .NET 2.0 SP1 (x64) from Official Microsoft Download Center
Den SQL Code, den man in einer Query hat, kann man dann über den o.g. Punkt den Code neu formatiert anzeigen lassen. Typisch ist das nötig, wenn man komplexe Stored Procedure in einer einzigen Zeile findet.
Sollte man eine Fehlermeldung sehen:
---------------------------
Microsoft SQL Server Management Studio
---------------------------
The 'FormatterPackage' package did not load correctly.
You can get more information by examining the file
‚C:\Users\frank.odenbreit\AppData\Roaming\Microsoft\AppEnv\14.0\ActivityLog.xml‘.
—————————
Ja Nein
—————————
https://github.com/TaoK/PoorMansTSqlFormatter/issues/187
EINFACH DEN DIALOG MIT „NO“ bzw. „NEIN“ BESTÄTIGEN!!!!
Siehe d. o.g. Link:
…
Don't bother reading all that text - I messed up the installer during the split at the start of the week.
The problem will have been temporary (as long as you say "No" in the error dialog, the extension loads fine on next SSMS restart and forever after), but still, almost 300 downloads of the bad installer... :(
Fixed installer is live, downloadable at http://architectshack.com/PoorMansTSqlFormatter.ashx
Sorry about the inconvenience.
…Ändern des SSAS Modus
C:\Program Files\Microsoft SQL Server\MSAS14.SQL2017\OLAP\Config
Wobei die hier Teile abhängig von der installierten Version sind.Datenbank shrinken, aber die Dateien werden nicht kleiner?
--Erst alle Indizes neu aufbauen
DECLARE @TableName varchar(255)
DECLARE TableCursor CURSOR FOR
SELECT DISTINCT QUOTENAME(TABLE_SCHEMA)+'.'+QUOTENAME(table_name)
FROM information_schema.tables
WHERE table_type = 'base table'
order by 1 asc
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
print @TableName+'....'
DBCC DBREINDEX(@TableName,' ',90)
FETCH NEXT FROM TableCursor INTO @TableName
END
CLOSE TableCursor
DEALLOCATE TableCursor
print 'FERTIG'
--Und nachher wirklich shrinken:
go
dbcc shrinkdatabase (0, 10, NOTRUNCATE)
--Erster Parameter := Aktuelle DB
--Zweiter Parameter := Wieviel Prozent soll "leer" bleiben
go
dbcc shrinkdatabase (0, 10, TRUNCATEONLY)
--dto.
GO
/*
--Quelle: https://qastack.com.de/server/31554/how-to-check-progress-of-dbcc-shrinkfile
--In einem anderem Fenster könnte man sehen wie weit der Shrink-Prozess ist:
select T.text, R.Status, R.Command, DatabaseName = db_name(R.database_id)
, R.cpu_time, R.total_elapsed_time, R.percent_complete as [ca.percent]
from sys.dm_exec_requests R
cross apply sys.dm_exec_sql_text(R.sql_handle) T
*/
SQL: Zahlen in lokalem Format
Speziell bei „Datum“ und „Zahlen“ hat man ständig mit Problemen.
Beispiel im SQL hat man ständig Werte wie „9999.99 aber im deutschem Excel wird nicht als 9.999,99“ verstanden und muss ständig mit hohem Zeitaufwand im Excel als „Text“ eingelesen und dann werden bei den betroffenen Spalten erst Punkt in Komma gewandelt und dann müsse die Spalten in die richtige Formate gebracht werden.
Bei DATUM lässt sich das in einer T-SQL Abfrage mit einem einfachen „SET“-Kommando anpassen. Leider gibt’s bisher keine einfache Lösung bei Microsoft.
Daher hilft möglicherweise der „FORMAT“-Befehl…
SELECT
-- c => currency
-- n => numeric
FORMAT(987654321, N'N', C.culture) AS some_number
, FORMAT(987654321, N'c', C.culture) AS some_currency
, C.culture
FROM
(
-- Language culture names
-- http://msdn.microsoft.com/en-us/library/ee825488(v=cs.20).aspx
VALUES
('en-US')
, ('en-GB')
, ('de-DE')
) C (culture);
Select FORMAT(987654321, N'N', 'de-DE') AS some_number
SSMS verbraucht CPU und reagiert nicht mehr alle paar Minuten…
Nebeninformation: CPU vom SSMS wird 15-25% und das RAM vom SSMS mehrere GB!![]()


https://superuser.com/questions/1195570/sql-server-management-studio-cpu-and-ram-usage-keeps-increasing-for-no-reasonEreignisanzeige/Events „ID 10016“
/*
Zugriff auf msdb und SSISDB
Link: https://docs.microsoft.com/en-us/sql/integration-services/security/integration-services-roles-ssis-service?view=sql-server-2017
Hinweis: Um SSIS-Jobs anzulegen, ist es meist notwendig weitere Einstellungen vorzunehmen, wie z.B. einen "Proxy".
*/
USE [SSISDB]
GO
CREATE USER [NT SERVICE\SQLAgent$SQL....] FOR LOGIN [NT SERVICE\SQLAgent$SQL....] WITH DEFAULT_SCHEMA=[dbo]
GO
EXEC sp_addrolemember @rolename = 'ssis_admin', @membername = 'NT SERVICE\SQLAgent$SQL....'
GO
USE [msdb]
GO
CREATE USER [NT SERVICE\SQLAgent$SQL....] FOR LOGIN [NT SERVICE\SQLAgent$SQL....] WITH DEFAULT_SCHEMA=[dbo]
GO
EXEC sp_addrolemember @rolename = 'db_ssisoperator', @membername = 'NT SERVICE\SQLAgent$SQL....'
GO
Wobei die Fehlermeldungen in der Ereignisanzeige nicht mehr auftraten.

SQL: Credentials und Proxy
SQL: Deploy SSIS-Solution





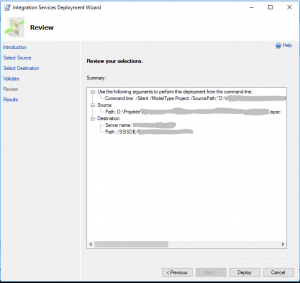
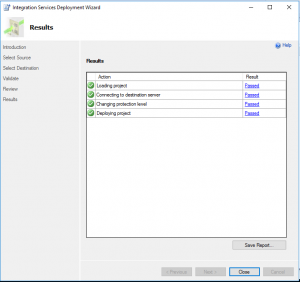
SQL: Agent Job anlegen








(Bitte die meinuser und meinlogin anpassen – und häufig sind beide gleichen Buchstabenfolge. Speziell bei AD-Usern und AB-Gruppen.)USE [SSISDB]
GO
CREATE USER [ meinuser ] FOR LOGIN [ meinlogin ] WITH DEFAULT_SCHEMA=[dbo]
GO
EXEC sp_addrolemember @rolename = 'ssis_admin', @membername = 'meinuser';
GO
USE [msdb]
GO
CREATE USER [ meinuser ] FOR LOGIN [ meinlogin ] WITH DEFAULT_SCHEMA=[dbo]
GO
EXEC sp_addrolemember @rolename = 'db_ssisoperator', @membername = 'meinuser';
GO
SQL: Transaktionen Try/Catch?
Begin Transaction
Begin Try
/*Insert/Update/…*/
End Try
Begin Catch
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
End Catch
IF @@TRANCOUNT > 0
COMMIT TRANSACTION;
/*Das Commit ist das "End Transaction"*/
SQL Server: Database Mail
Ähnliche Beschreibungen:
http://sqlcache.blogspot.com/2014/11/sql-server-database-mail.html
https://www.gevitas.de/wiki/index.php?title=E-Mails_mit_dem_Microsoft-SQL-Server

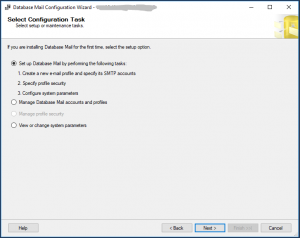


Wir empfehlen dafür einen eigenen Exchange Account und dies mit dem IT-Administratoren abzusprechen – also eigentlich wie ein normaler Anwender.
Z.B. könnte dieser heißen wie „SQLServer“.
Möglicherweise ist aber bei Ihnen bei allen anderen SQL Servern auch schon Database Mail eingerichtet und der gleiche Account benutzt ist. Dazu meist nur benutzt bei kritischen Fehlern an alle Admins versendet werden. Wir werden jedoch vermutlich regelmäßig mehr versenden als nur bei Fehlern.
Noch einmal: Dieser „Account“ wird nur E-Mail versenden und nie E-Mail „lesen“ – Also falls E-Mails eingehen, werden diese ewig in dem Postfach liegen bleiben.
(„Reply e-mail“ bitte genauso eintragen, wie die „E-mail address“)
Links Information über E-Mail Server:
https://support.office.com/de-de/article/server-einstellungen-die-sie-von-ihrem-e-mail-anbieter-benötigen-c82de912-adcc-4787-8283-45a1161f3cc3





https://blog.sqlauthority.com/2018/06/30/sql-server-database-mail-error-the-smtp-server-requires-a-secure-connection-or-the-client-was-not-authenticated-the-server-response-sas-5-5-1/
Leider hilft die spezielle SQL Server 2017 – Site gar nicht:
https://docs.microsoft.com/de-de/sql/relational-databases/database-mail/configure-database-mail?view=sql-server-2017
https://docs.microsoft.com/de-de/sql/relational-databases/system-stored-procedures/sp-send-dbmail-transact-sql?view=sql-server-2017
Failed to initialize sqlcmd library with error number -2147467259.Zugriff auf SQL Server über eine AD-Gruppe
USE [master]
GO
CREATE LOGIN [Domäne\Domänen-Benutzer] FROM WINDOWS WITH DEFAULT_DATABASE=[master]
GO
USE [Datenbank]
GO
CREATE USER [Domäne\Domänen-Benutzer] FOR LOGIN [Domäne\Domänen-Benutzer]
GO

Indizes aktualisieren….
/**************************************************************
Bitte als SYSDBA anmelden.
DEFRAGMENTATION von Indizes - es ist nicht notwendig zusätzliche
Bibliotheken aufzurufen
ACHTUNG: HIER SIND ZWEI STELLEN FREIZUSCHALTEN!!!
HINWEIS: die richtige DB festlegen
***************************************************************/
use --FranksDB
go
--Hier ist bewusst ein Fehler eingebaut, damit die DB korrekt festgelegt ist
--DEFRAGMENTATION:
SET NOCOUNT ON;
DECLARE @objectid int;
DECLARE @indexid int;
DECLARE @partitioncount bigint;
DECLARE @schemaname sysname;
DECLARE @objectname sysname;
DECLARE @indexname sysname;
DECLARE @partitionnum bigint;
DECLARE @partitions bigint;
DECLARE @frag float;
DECLARE @command varchar(8000);
-- ensure the temporary table does not exist
IF EXISTS (SELECT name FROM sys.objects WHERE name = 'work_to_do')
DROP TABLE work_to_do;
--diesen parameter "DB_ID()" darf man nicht benutzten - wieso auch immmer
DECLARE @DBID bigint;
select @DBID=DB_ID();
-- conditionally select from the function, converting object and index IDs to names.
SELECT object_id AS objectid,
index_id AS indexid,
partition_number AS partitionnum,
avg_fragmentation_in_percent AS frag
INTO work_to_do
FROM sys.dm_db_index_physical_stats (@DBID, NULL, NULL , NULL, 'LIMITED')
WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0;
-- Declare the cursor for the list of partitions to be processed.
DECLARE partitions CURSOR FOR SELECT * FROM work_to_do;
-- Open the cursor.
OPEN partitions;
-- Loop through the partitions.
FETCH NEXT
FROM partitions
INTO @objectid, @indexid, @partitionnum, @frag;
WHILE @@FETCH_STATUS = 0
BEGIN;
SELECT @objectname = o.name, @schemaname = s.name
FROM sys.objects AS o
JOIN sys.schemas as s ON s.schema_id = o.schema_id
WHERE o.object_id = @objectid;
SELECT @indexname = name FROM sys.indexes WHERE object_id = @objectid AND index_id = @indexid;
SELECT @partitioncount = count (*) FROM sys.partitions WHERE object_id = @objectid AND index_id = @indexid;
-- 30 is an arbitrary decision point at which to switch between reorganizing and rebuilding
IF @frag <= 10.0
BEGIN;
SELECT @command = 'Index: [' + @indexname + '] ON [' + @schemaname + '].[' + @objectname + ']...OK';
END;
IF @frag > 10.0 AND @frag <= 30.0
BEGIN;
SELECT @command = 'ALTER INDEX [' + @indexname + '] ON [' + @schemaname + '].[' + @objectname + '] REORGANIZE';
IF @partitioncount > 1
SELECT @command = @command + ' PARTITION=' + CONVERT (CHAR, @partitionnum);
--EXEC (@command); -----HIER FREISCHALTEN!!!!!
END;
IF @frag > 30.0
BEGIN;
SELECT @command = 'ALTER INDEX [' + @indexname +'] ON [' + @schemaname + '].[' + @objectname + '] REBUILD';
IF @partitioncount > 1
SELECT @command = @command + ' PARTITION=' + CONVERT (CHAR, @partitionnum);
--EXEC (@command); -----HIER FREISCHALTEN!!!!!
END;
PRINT 'Executed ' + @command;
FETCH NEXT FROM partitions INTO @objectid, @indexid, @partitionnum, @frag;
END;
-- Close and deallocate the cursor.
CLOSE partitions;
DEALLOCATE partitions;
-- drop the temporary table
--Select * from work_to_do
IF EXISTS (SELECT name FROM sys.objects WHERE name = 'work_to_do')
DROP TABLE work_to_do;
-- FERTIG Meldung
PRINT 'All Indices was reorganized or rebuilded. '
SQL: Index über ein View? Schemabinding ist die Lösung – aber nicht immer…
SELECT
SESSIONPROPERTY ('NUMERIC_ROUNDABORT') as "NUMERIC_ROUNDABORT soll 0",
SESSIONPROPERTY ('ANSI_PADDING') as "ANSI_PADDING soll 1",
SESSIONPROPERTY ('ANSI_WARNINGS') as "ANSI_WARNINGS soll 1",
SESSIONPROPERTY ('CONCAT_NULL_YIELDS_NULL') as "CONCAT_NULL_YIELDS_NULL soll 1",
SESSIONPROPERTY ('ARITHABORT') as "ARITHABORT soll 1",
SESSIONPROPERTY ('QUOTED_IDENTIFIER') as "QUOTED_IDENTIFIER soll 1" ,
SESSIONPROPERTY ('ANSI_NULLS') "ANSI_NULLS soll 1"
SQL: Mehrere Sätze als einzelner String zusammenfassen
DECLARE @T TABLE (t uniqueidentifier)
Insert into @T
Select '19324C4B-83AE-E211-83C9-005056B05853'
union all
Select '99324C4B-83AE-E211-83C9-005056B05800'
--Mehrere Sätze als einzelner String zusammenfassen:
SELECT STUFF(
(
SELECT ','+CAST(t as varchar(38))
FROM @t
FOR XML PATH ('')
)
,1,1,'')
Dynamisches SQL – Beispiel „Anzahl von Sätzen allen Tabellen“
DECLARE @Schema nvarchar(64) = 'dbo'
DECLARE @SQL nvarchar(max)
DECLARE @ParmDefinition nvarchar(max) = '@CountOUT int OUTPUT'
DECLARE @Count bigint
Select @SQL='SELECT @CountOUT = '+STRING_AGG('(Select count(1) from ['+[schemas].[name]+'].['+[tables].[name]+'])','+')
from sys.tables tables left outer join sys.schemas schemas on schemas.schema_id=tables.schema_id
where [tables].[type]='U'
and [schemas].[name] like @Schema
EXEC sp_executesql @SQL, @ParmDefinition, @CountOUT=@Count OUT
Select @Count as TotalRowsSQL Server Icons mit blauem Fragezeichen?
SQL Server: Welcher Port wird vom SQL Server genutzt?
netstat -ano
Aber das macht eine zu lange Liste…
Kurzer Test ob der Standard Port 1433 festgelegt ist:
netstat -ano | findstr 1433
Aber wenn das nichts bringt, dann den SQL Server selber fragen:
SELECT DISTINCT
local_tcp_port
FROM sys.dm_exec_connections
WHERE local_tcp_port IS NOT NULL
T-SQL Settings: LANGUAGE, Dateformat und DATEFIRST
--Save the old / usual settings:
DECLARE @DATEFIRST int = @@DATEFIRST
DECLARE @LANGUAGE nvarchar(100) = @@LANGUAGE
DECLARE @DATEFORMAT nvarchar(100) = (
select s.date_format
from sys.dm_exec_sessions s
where s.session_id = @@SPID
)
--Set new temporary Settings:
SET DATEFIRST 7;
SET DATEFORMAT mdy;
SET LANGUAGE US_ENGLISH;
…
…
--Restore the saved settings:
SET LANGUAGE @language; /*Germany: "Deutsch" */
SET DATEFIRST @DATEFIRST; /*Germany: "dmy" */
SET DATEFORMAT @DATEFORMAT; /*Germany: "1" */
Wie auch immer, solche Einstellungen gelten ohnehin nur in aktuellen Session.T-SQL: Fehlende Indizes…

-- Missing Index Script
-- Original Author: Pinal Dave (C) 2011
-- verändert von Frank Odenbreit 2011/2013/2016
/*
Es werden zwar die 50 wichtigsten Indizes geholt und diese nachher sortiert nach ihrem Namen
(Ähnlichkeiten sollte man erkennen können, ggf. anpassen bzw. aus kommentieren)
*/
Select *
from (
SELECT TOP 50
dm_mid.database_id AS DatabaseID,
dm_migs.user_seeks as user_seeks,
dm_migs.avg_user_impact as avg_user_impact,
dm_migs.avg_user_impact * (dm_migs.user_seeks+dm_migs.user_scans) AS Avg_Estimated_Impact,
dm_migs.last_user_seek AS Last_User_Seek, object_name(dm_mid.object_id) AS [TableName],
--*,
'CREATE NONCLUSTERED INDEX [ndx' + object_name(dm_mid.object_id) + '__'
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.equality_columns,''),', ','_'),'[',''),']','') +
CASE
WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.inequality_columns,''),', ','_'),'[',''),']','')
+ ']'
+ ' ON ' + dm_mid.statement + ' (' + ISNULL (dm_mid.equality_columns,'')
+ CASE WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN ',' ELSE
'' END
+ ISNULL (dm_mid.inequality_columns, '')
+ ')'
+ ISNULL (' INCLUDE (' + dm_mid.included_columns + ')', '')
+ ' WITH (pad_index=OFF,Fillfactor=90,ignore_dup_key=OFF,allow_row_locks=ON,allow_page_locks=ON,DROP_EXISTING = OFF, ONLINE = OFF) ON [PRIMARY]'
AS Create_Statement
FROM sys.dm_db_missing_index_groups dm_mig
INNER JOIN sys.dm_db_missing_index_group_stats dm_migs ON dm_migs.group_handle = dm_mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details dm_mid ON dm_mig.index_handle = dm_mid.index_handle
WHERE dm_mid.database_ID = DB_ID()
ORDER BY Avg_Estimated_Impact DESC
) as t
order by Create_Statement asc
SQL: „Create Schema“ nur nach Bedingung…
IF SCHEMA_ID('STG') IS NULL
BEGIN
CREATE SCHEMA [STG]
END
GO
Msg 156, Level 15, State 1, Line 5
Incorrect syntax near the keyword 'SCHEMA'.
IF SCHEMA_ID('STG') is NULL
BEGIN
EXEC sp_executesql N'CREATE SCHEMA [STG]'
END
GO
SQL: Rekursive Abfragen
/*
Hierarchie von Firmen
---------------------
Egal wo man steht, erst den obersten ParentAccount suchen
und von dort aus alle Kinder feststellen
--http://www.bidn.com/blogs/KeithHyer/bidn-blog/2293/hierarchy-with-recursive-cte-and-a-little-borrowed-sorting-trickery
*/
/*Muster MSCRM BusinessUnit:*/
--Select Name, * from Team order by 1
With hBU(Name, BusinessUnitId, ParentBusinessUnitIdName, ParentBusinessUnitId, Levl, sortBU)
As (
/*Anker*/
Select Name, BusinessUnitId, ParentBusinessUnitIdName, ParentBusinessUnitId , 0 Levl , CONVERT( VARchar(MAX) , ( BusinessUnit.Name ) ) as sortBU
From BusinessUnit
Where ParentBusinessUnitId IS NULL /*and Name = 'dkacrm'*/
union all
/*Recursion*/
Select BusinessUnit.Name, BusinessUnit.BusinessUnitId, BusinessUnit.ParentBusinessUnitIdName, BusinessUnit.ParentBusinessUnitId , Levl + 1 as Levl, CONVERT( VARchar(MAX) , ( SortBU + BusinessUnit.Name ) ) as sortBU
From BusinessUnit
inner join hBU on hBU.BusinessUnitId = BusinessUnit.ParentBusinessUnitId
Where BusinessUnit.ParentBusinessUnitId IS NOT NULL
)
Select coalesce(replicate(char(124)+' ',Levl-1)+replicate(char(43)+' ',Levl-Levl+1) ,'') + hBU.Name , *
from hBU
order by sortBU
/*Muster MSCRM Account:
Wobei die Felder CustomerTypeCode und ImportSequenceNumber nur Firmen/Kunden-spezifisch sind
*/
With hAcc(Name, Accountid, ParentAccountIdName, ParentAccountid, CustomerTypeCode, ImportSequenceNumber, Levl, SortAcc)
As (
/*Anker*/
Select Name, AccountId, ParentAccountIdName, ParentAccountId, CustomerTypeCode, ImportSequenceNumber, 0 Levl, CONVERT( Varchar(MAX) , Name ) as SortAcc
From Account
Where 1=1
and CustomerTypeCode in (200002 /*Debitoren*/, 200000 /*Filialen*/)
and ParentAccountId IS NULL
union all
/*Recursion in CTE*/
Select Account.Name, Account.AccountId, Account.ParentAccountIdName, Account.ParentAccountId, Account.CustomerTypeCode, Account.ImportSequenceNumber, Levl + 1, CONVERT( Varchar(MAX) , SortAcc + Account.Name ) as SortAcc
From Account
inner join hAcc on hAcc.Accountid=Account.ParentAccountId
Where 1=1
and Account.CustomerTypeCode in (200002 /*Debitoren*/, 200000 /*Filialen*/)
and Account.ParentAccountId IS NOT NULL
)
Select coalesce(replicate(char(124)+' ',Levl-1)+replicate(char(43)+' ',Levl-Levl+1) ,'') + Name as Name,
CustomerTypeCode, StringMap.Value as CustomerTypeCodeReadable,
/*Case when CustomerTypeCode = 200000 then 'Filiale' when CustomerTypeCode = 200002 Then 'Debitor' else '???' end CustomerTypeCodeReadable,*/
AccountId, ParentAccountId, ParentAccountIdName, CustomerTypeCode, ImportSequenceNumber, Levl
From hAcc
left outer join StringMap on StringMap.AttributeName = 'CustomerTypeCode' and StringMap.LangId = 1031 and StringMap.AttributeValue = hAcc.CustomerTypeCode
Order by SortAcc
/*Muster SLX Account:*/
Declare @Ankerid char(12);
SET @Ankerid = 'A6UNMA000DQO'; --z.B. Firma Muster GmbH & Co. KG (ist ein Kind weil es ein Parent hat)
--SET @Ankerid = 'A6UJ9A00050W'; --z.B. Muster Holding AG (ist OberAccount)
--Von hier aus den Obervater finden:
DECLARE @ToplevelAccountid char(12);
WITH hAcc(Account, Accountid, ParentAccountid, Levl)
AS (
--Anker:
Select Account, Accountid, Parentid AccountParentid, 0 Levl
from Account
where Accountid=@Ankerid
union all
--Rekursion in CTE:
Select Account.Account Account, Account.Accountid Accountid, Account.Parentid ParentAccountid, Levl + 1
from Account
inner join hAcc on hAcc.ParentAccountid = Account.Accountid
--where Parentid IS NOT NULL
)
--Select Account, Accountid, ParentAccountid, Levl from hAcc where ParentAccountid IS NULL
Select @ToplevelAccountid = Accountid from hAcc where ParentAccountid IS NULL;
--Print @ToplevelAccountid
--Von hier aus alle Kinder:
WITH hAcc(Account, Accountid, ParentAccount, ParentAccountid, Levl, SortAcc)
AS (
--Anker (also alle Sätze, die keine Kinder mehr haben):
Select Account, Accountid, cast(NULL AS Varchar(128)) ParentAccount, Parentid ParentAccountid, 0 Levl
,CONVERT( VARchar(MAX) , Account ) as SortAcc
from Account
where Parentid IS NULL
and Accountid=@ToplevelAccountid
union all
--Rekursion in CTE:
Select Account.Account Account, Account.Accountid Accountid, hAcc.Account ParentAccount, Account.Parentid ParentAccountid, Levl + 1
, CONVERT( VARchar(MAX) , ( SortAcc + Account.Account ) ) as SortAcc
from Account
inner join hAcc on hAcc.Accountid=Account.Parentid
where Parentid IS NOT NULL
)
Select
Account Account,
coalesce(replicate(char(124)+' ',Levl-1)+replicate(char(43)+' ',Levl-Levl+1) ,'') Leveling,
'' FirstChar,
Accountid, ParentAccount, ParentAccountid, Levl,
(Case when @Ankerid = Accountid Then 1 else 0 end) Markierung
,SortAcc
--,Row_Number() Over(order by SortAcc asc) RowNum
from hAcc
order by SortAcc
/*
--Beispiel:
Select parentid, Account, Accountid from Account where Accountid='A6UJ9A000F01'
Select parentid, Account, Accountid from Account where Accountid='A6UJ9A00050W'
*/
Select * from account
Select * from gc_account_ext
Select * from ACC_CORPORATE
Select a.ACCOUNT, a.ACCOUNTID, ac.ACCOUNTID, ac.ACC_PARENTID
from account a
inner join ACC_CORPORATE ac on a.ACCOUNTID=ac.ACCOUNTID
;WITH LoopIT( PARENT, CHILD )
AS (
--Anker (also alle Sätze, die keine Kinder mehr haben):
Select ac.ACC_PARENTID, ac.ACCOUNTID
From ACC_CORPORATE ac
where ac.ACC_PARENTID NOT IN (Select ac2.ACCOUNTID From ACC_CORPORATE ac2)
union all
--Rekursion in CTE:
Select r.ACC_PARENTID, r.ACCOUNTID
From LoopIT r
inner join ACC_CORPORATE acr on r.ACCOUNTID = acr.ACC_PARENTID
)
Select PARENT, CHILD FROM LoopIT
OPTION (MAXRECURSION 32767)
Speicher Situation eines SQL Servers
/**************************************************************
Wieviel Platz ist auf dem Filesystem des SQL Servers
und wie wird der RAM benutzt?
***************************************************************/
DECLARE @DB varchar(255)
SET @DB = --'FOD_Test_DB'
--Hier ist bewusst ein Fehler eingebaut, damit die DB korrekt festgelegt ist
/*
Physikalische Größe und freien Speicher in den Datenbanken
*/
exec ('use '+@DB+';
select
name
, filename
, convert(decimal(12,2),round(a.size/128.000,2)) as FileSizeMB
, convert(decimal(12,2),round(fileproperty(a.name,''SpaceUsed'')/128.000,2)) as SpaceUsedMB
, convert(decimal(12,2),round((a.size-fileproperty(a.name,''SpaceUsed''))/128.000,2)) as FreeSpaceMB
from dbo.sysfiles a;'+
'use '+'tempdb'+';
select
name
, filename
, convert(decimal(12,2),round(a.size/128.000,2)) as FileSizeMB
, convert(decimal(12,2),round(fileproperty(a.name,''SpaceUsed'')/128.000,2)) as SpaceUsedMB
, convert(decimal(12,2),round((a.size-fileproperty(a.name,''SpaceUsed''))/128.000,2)) as FreeSpaceMB
from dbo.sysfiles a')
/*
Freier Speicher im Filesystem des SQL-Servers:
*/
exec xp_fixeddrives
/*
Aufteilung des Arbeitspeicher des Systems
*/
/*
Select * from sys.dm_os_memory_pools
Select * from sys.dm_os_memory_allocations
Select * from sys.dm_os_memory_clerks
Select * from sys.dm_os_memory_objects
Select * from sys.dm_os_memory_nodes
--Ab SQL Server 2008 möglich:
Select cast(round(total_physical_memory_kb/1024.0/1024.0,2) as decimal(10,2)) PhysicalRAM_GB
,cast(round(available_physical_memory_kb/1024.0/1024.0,2) as decimal(10,2)) AvailableRAM_GB
,*
from sys.dm_os_sys_memory
*/
SQL: Binäre Darstellung wandeln in Integer (’0101′ => 5)
/*
Binary to Decimal
Zwei Teile:
1) Stored Function
2) CTE, ohne Function!
--MUSTER:
--select sysdba.fod_Int2Binary(5242881)
select sysdba.fod_Binary2Int('00000000010100000000000000000001', 17, 32)
*/
IF EXISTS (select name, * from sysobjects where name = 'fod_Binary2Int' and Type = 'FN') Drop function fod_Binary2Int
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author:
SQL: Integer wandeln in Binäre Darstellung (5=>’0101′)
/*
Integer => Binär
Zwei Varianten:
1) Stored Function
2) T-SQL, ohne Function
--MUSTER:
select sysdba.fod_Int2Binary(5242881)
--select sysdba.fod_Binary2Int('00000000010100000000000000000001', 17, 32)
*/
IF EXISTS (select name, * from sysobjects where name = 'fod_Int2Binary' and Type = 'FN') Drop function fod_Int2Binary
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author:
MS SQL: SQL-Code von Views, Trigger Prozeduren und Funktionen darstellen
/*
Darstellen von SQL Code von Views. Trigger, Prozeduren und Funktionen
*/
Select s.name, m.definition
from sys.sql_modules m inner join sys.views s ON s.object_id = m.object_id
where 1=1
Select s.name, m.definition
from sys.sql_modules m inner join sys.triggers s ON s.object_id = m.object_id
where 1=1
Select s.name, m.definition
from sys.sql_modules m inner join sys.procedures s ON s.object_id = m.object_id
where 1=1
order by 1
Select s.name, m.definition
from sys.sql_modules m inner join sys.objects s on s.object_id = m.object_id and s.Type='FN'
where 1=1
order by 1
Problem 2: Code ist möglw. länger als 4000/8000 Zeichen
Problem 3: Code ist möglw. verschlüsseltMS SQL: Wie weit ist das Datenbank Backup? Wie viele Prozent sind durch?
/*
Wenn ein Backup länger lauft, kann man feststellen wie weit das Backup ist.
Ggf. hilft diese Recht zum Lesen dieses Code auch anderen geben:
GRANT VIEW SERVER STATE TO [sqluser_loginname]
*/
Select Session_id asSPID, r.database_id, r.command, a.text as Query, start_time, percent_complete,
DATEADD(Second, estimated_completion_time/1000, GetDate()) as estimated_completion_time
From sys.dm_exec_requests r cross Apply sys.dm_exec_sql_text(r.sql_handle) a
Where r.command in ('Backup Database', 'Restore Database', 'Backup Log')
MS SQL: Wie lange dauert es noch bis die Datenbank wiederhergestellt ist?
/*
http://timlaqua.com/2009/09/determining-how-long-a-database-will-be-in-recovery-sql-server-2008/
ACHTUNG: CODE UNTERSCHIEDLICH VOR SQL SERVER 2012:
sys.xp_readerrorlog
sys.sp_readerrorlog
*/
DECLARE @Serverversion integer = 2012 --BITTE CODE VORHER LESEN!!!!
DECLARE @DBName VARCHAR(64) = 'databasename'
If @Serverversion > 2012
BEGIN
/*
----------------------------
SQL Server 2008
----------------------------
So, your MSSQL service crashed in the middle of a big transaction? Or you bumped the service while it was rolling back some gigantic schema change (like say a column add on a 800 million row table)? Well, as you prepare your resume in preparation for the fallout from this debockle, you can use the following query to see how much time you have left. Or, I should say, how much time it thinks you have left... which seems to swing wildly up and down... microsoft math ftw.
*/
DECLARE @ErrorLog AS TABLE([LogDate] CHAR(24), [ProcessInfo] VARCHAR(64), [TEXT] VARCHAR(MAX))
INSERT INTO @ErrorLog
EXEC sys.xp_readerrorlog 0, 1, 'Recovery of database', @DBName
SELECT TOP 5
[LogDate]
,SUBSTRING([TEXT], CHARINDEX(') is ', [TEXT]) + 4,CHARINDEX(' complete (', [TEXT]) - CHARINDEX(') is ', [TEXT]) - 4) AS PercentComplete
,CAST(SUBSTRING([TEXT], CHARINDEX('approximately', [TEXT]) + 13,CHARINDEX(' seconds remain', [TEXT]) - CHARINDEX('approximately', [TEXT]) - 13) AS FLOAT)/60.0 AS MinutesRemaining
,CAST(SUBSTRING([TEXT], CHARINDEX('approximately', [TEXT]) + 13,CHARINDEX(' seconds remain', [TEXT]) - CHARINDEX('approximately', [TEXT]) - 13) AS FLOAT)/60.0/60.0 AS HoursRemaining
,[TEXT]
FROM @ErrorLog
ORDER BY 1 DESC
END
Else
BEGIN
/*
----------------------------
Sql Server 2012
----------------------------
uses a different stored procedure to read the error log:
*/
DECLARE @ErrorLog AS TABLE([LogDate] CHAR(24), [ProcessInfo] VARCHAR(64), [TEXT] VARCHAR(MAX))
INSERT INTO @ErrorLog
EXEC master..sp_readerrorlog 0, 1, 'Recovery of database', @DBName
SELECT TOP 5
[LogDate]
,SUBSTRING([TEXT], CHARINDEX(') is ', [TEXT]) + 4,CHARINDEX(' complete (', [TEXT]) - CHARINDEX(') is ', [TEXT]) - 4) AS PercentComplete
,CAST(SUBSTRING([TEXT], CHARINDEX('approximately', [TEXT]) + 13,CHARINDEX(' seconds remain', [TEXT]) - CHARINDEX('approximately', [TEXT]) - 13) AS FLOAT)/60.0 AS MinutesRemaining
,CAST(SUBSTRING([TEXT], CHARINDEX('approximately', [TEXT]) + 13,CHARINDEX(' seconds remain', [TEXT]) - CHARINDEX('approximately', [TEXT]) - 13) AS FLOAT)/60.0/60.0 AS HoursRemaining
,[TEXT]
FROM @ErrorLog
ORDER BY 1 DESC, 2 DESC, 3 DESC
END
Quelle: http://timlaqua.com/2009/09/determining-how-long-a-database-will-be-in-recovery-sql-server-2008/
Kommaseparierte Liste – Explode (string_split)
Diese Funktion wird als Tabelle aufgerufen und hat nur die Spalte „value“:
/*Test Tabelle und Daten bereitstellen:*/
DECLARE @Test TABLE (id int identity(1,1) NOT NULL, wert nvarchar(MAX) NULL)
INSERT INTO @test VALUES ('a,b,c,d,e,f'), ('1,2,3,4,5,6,7,8,9'), ('aa,bb,cc,dd,ee,ff,gg')
--Select * from @Test
/*Daten aus einem Feld als Tabelle bereitstellen:*/
Select value
from @Test
outer apply string_split(wert,',')
where id = 3
Funktion: Jahr, Monat und Tag als „Datetime“…
IF EXISTS (select name, * from sysobjects where name = 'fod_YMD2Datetime' and Type = 'FN') Drop function fod_YMD2Datetime
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION fod_YMD2Datetime(@Year int, @Month int, @Day int)
RETURNS datetime
AS
-- =============================================
-- Author: FOd
-- Create date: <2009-01-30>
-- Description: Aus Jahr, Monat und Tag ein Datetime liefern
-- =============================================
BEGIN
DECLARE @d datetime;
SET @d = dateadd(year,(@Year - 1753),'1/1/1753');
SET @d = dateadd(month,@Month - 1,@d);
SET @d = dateadd(day, @Day - 1, @d);
RETURN @d
END
go
--Select dbo.gc_YMD2Datetime(2009, 1, 30)
SYSTEM_VERSIONING (Temporal Tables)
A system-versioned temporal table is a type of user table designed to keep a full history of data changes and allow easy point in time analysis. This type of temporal table is referred to as a system-versioned temporal table because the period of validity for each row is managed by the system
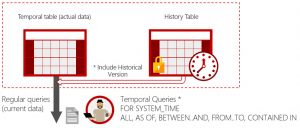
(Quelle: https://docs.microsoft.com/en-us/sql/relational-databases/tables/temporal-tables)SELECT *
FROM Employee
FOR SYSTEM_TIME
BETWEEN '2014-01-01 00:00:00.0000000'
AND '2015-01-01 00:00:00.0000000'